

Rápida, detallada y precisa, Stable Diffusion ha ampliado los límites de la inteligencia artificial con sus prometedores resultados.
Stable Diffusion es un modelo de difusión de IA de texto a imagen que genera imágenes únicas mediante métodos avanzados de aprendizaje profundo.
También puede crear vídeos y animaciones a partir de indicaciones de texto. Stable Diffusion utiliza un modelo de difusión que transforma el ruido aleatorio en imágenes coherentes mediante un proceso de refinamiento constante, ¡ofreciéndote a cambio contenido generado de forma única!
¿Quieres saber cómo funciona?
En este artículo, analizaremos el proceso de funcionamiento del modelo de IA generativa, sus aplicaciones y cómo acceder a él.
Puntos clave
-
Stable Diffusion es un modelo de IA generativa que se utiliza para crear imágenes a partir de indicaciones de texto.
-
Utiliza tecnología de difusión latente para un procesamiento eficiente.
-
Stable Diffusion se puede utilizar para generar videoclips y animaciones.
-
El modelo generativo se puede instalar y ejecutar en dispositivos locales o en servicios en la nube.
-
Es de código abierto.
¿Qué es Stable Diffusion?
Stable Diffusion es un modelo de IA basado en el aprendizaje profundo que genera imágenes únicas a partir de indicaciones de texto utilizando técnicas de difusión.
El modelo también puede generar vídeos, animaciones, reconstrucciones de zonas ocultas y ampliaciones de zonas ocultas, entre otras cosas. Se ha desarrollado a partir de miles de millones de imágenes utilizadas como datos de entrenamiento, lo que le permite generar imágenes detalladas y realistas.
Lo mejor de Stable Diffusion es que el código y los pesos del modelo son de código abierto, lo que permite a todo el mundo acceder al modelo en su propio equipo.
Para ello, necesitas un ordenador de sobremesa o portátil con una tarjeta gráfica capaz de funcionar con al menos 4 GB de VRAM (memoria de acceso aleatorio para gráficos).
Esto confiere a Stable Diffusion una mayor flexibilidad en comparación con otros modelos de conversión de texto a imagen a los que solo se puede acceder a través de servicios en la nube.
¡Vamos a ver cómo funciona!
¿Cómo funciona Stable Diffusion?
El modelo Stable Diffusion opera en el espacio latente. El espacio latente es un espacio vectorial multidimensional en el que se agrupan elementos y datos similares. Se utiliza en la inteligencia artificial para comprimir los datos y captar su estructura subyacente.
El uso del espacio latente reduce considerablemente los requisitos de procesamiento. Esto permite que la IA se ejecute en dispositivos locales con una capacidad mínima de GPU de 6 GB de VRAM.
Este método de compresión ahorra una gran cantidad de recursos de procesamiento.
Entonces, ¿cómo funciona?
Stable Diffusion utiliza estos tres componentes principales para la difusión latente:
-
Autoencoder variacional (VAE)
-
U-Net
-
Decodificador VAE
Veamos cómo funciona cada componente en la creación de una imagen generada por IA.
Autoencoder variacional (VAE)
El autoencoder de variación es una técnica que se utiliza para comprimir la imagen en el espacio latente.
El VAE consta de dos componentes:
-
Codificador
-
Decodificador
La imagen se comprime en el espacio latente mediante el codificador. Posteriormente, el decodificador restaura la imagen a partir de su formato comprimido.
Mediante el codificador, una imagen de 512x512x3 se convierte en una de 64x64x4 para el proceso de difusión. Estas pequeñas imágenes codificadas se denominan «latentes».
En cada fase del entrenamiento se añade más ruido al dato latente.
U-Net
U-Net es un predictor de ruido que introduce primero la representación latente y la indicación de texto antes de predecir la representación sin ruido de la representación latente ruidosa.
La sustracción de ruido se lleva a cabo para eliminar el ruido presente en la imagen latente inicial. Esto genera una imagen latente completamente nueva y limpia.
Este proceso se repite un número determinado de veces antes de enviar la señal latente al decodificador.
Decodificador VAE
Por último, el espacio latente se convierte de nuevo en espacio de píxeles mediante el decodificador. Esto genera el producto final.
Y con esto concluye la descripción de la arquitectura de Stable Diffusion.
¿Para qué sirve Stable Diffusion?
Stable Diffusion destaca por su notable mejora con respecto a otros modelos de generación de imágenes a partir de texto. Requiere menos potencia de procesamiento y, al mismo tiempo, ofrece resultados significativamente mejores.
Entonces, ¿qué hace Stable Diffusion?
La respuesta es: «¡Muchas cosas!»
Estas son algunas de las cosas que puedes crear con Stable Diffusion:
Generación de imágenes a partir de texto
Stable Diffusion destaca por su capacidad para generar imágenes visualmente coherentes a partir de indicaciones de texto. Si deseas incorporar la generación de imágenes mediante IA a tu aplicación, sitio web o cualquier otro proyecto, te recomendamos que utilices laAPI de SDXL.
Utiliza los datos de entrenamiento para generar imágenes empleando números de semilla ajustados para el generador aleatorio. Se pueden conseguir diferentes efectos modificando el esquema de eliminación de ruido.
Generación de imágenes a partir de imágenes
También puedes generar nuevas imágenes a partir de una imagen ya existente utilizando una indicación de texto.
Se puede utilizar para añadir efectos a la imagen de entrada.
Por ejemplo, probé con «Una librería local en un barrio residencial con un perro delante» en stablediffusionweb.com y me dio el siguiente resultado:
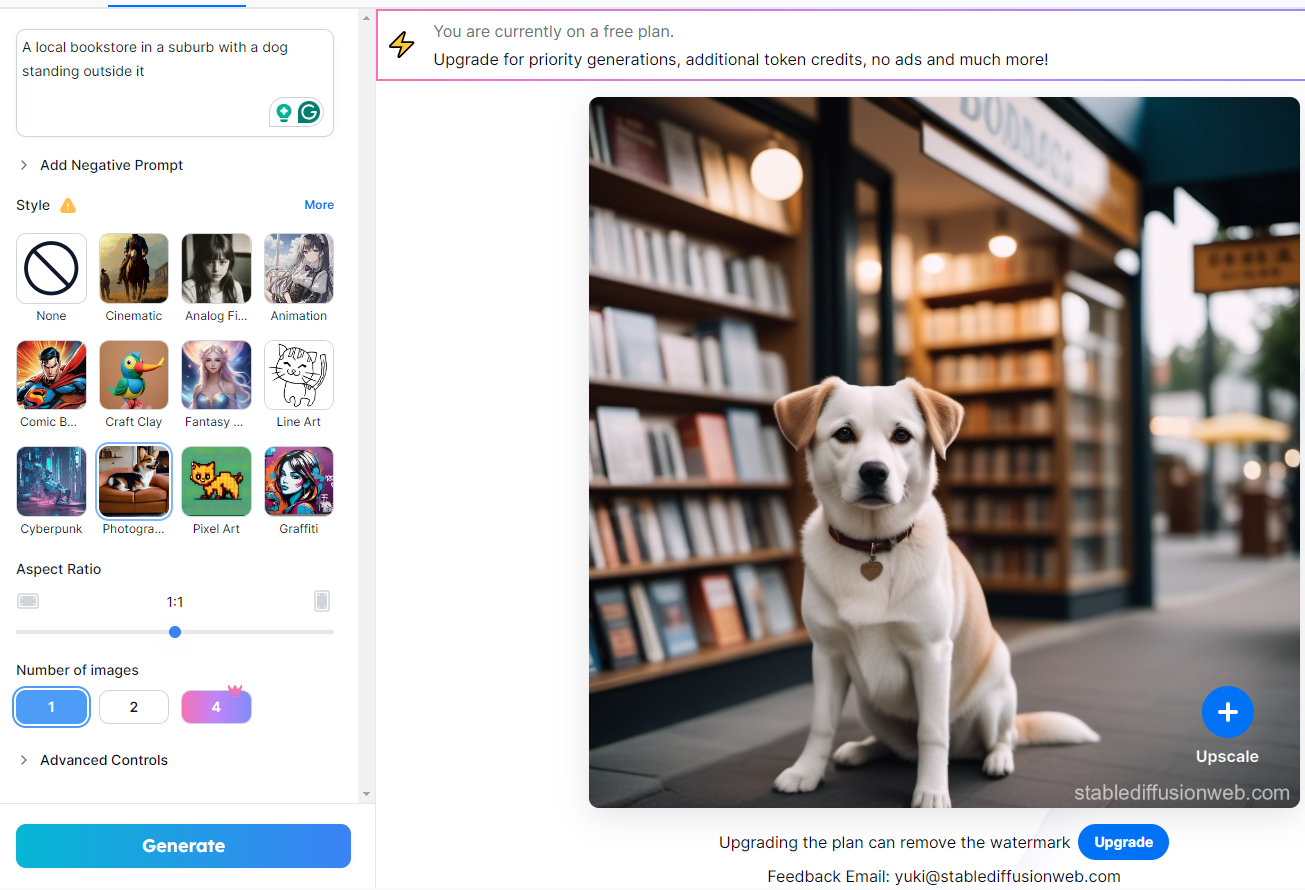
Creación de gráficos, ilustraciones y logotipos
Stable Diffusion te ofrece la libertad creativa necesaria para personalizar la creación de tu logotipo mediante un boceto e instrucciones detalladas para el resultado final.
Con él, podrás crear tus ilustraciones, diseños, logotipos y otros contenidos con una amplia variedad de estilos.
Relleno
El relleno de huecos es un proceso que se utiliza para restaurar o completar zonas concretas de una imagen mediante la generación de imágenes a partir de otras imágenes.
Puedes reconstruir cualquier imagen dañada o corrupta siguiendo unas instrucciones concretas.
Creación de vídeos
Las funciones de Stable Diffusion, como Deforum de GitHub, pueden ayudarte a crear vídeos cortos y animaciones. También puedes aplicar tu estilo preferido al vídeo.
El modelo genera varias imágenes y las anima para crear la sensación de movimiento.
Cómo utilizar Stable Diffusion
Hasta ahora hemos aprendido qué es Stable Diffusion y cómo funciona. Pero,¿cómo se utiliza Stable Diffusion?
Aquí tienes tres formas de acceder a Stable Diffusion para generar imágenes únicas con IA:
-
Cómo utilizar Stable Diffusion Online
-
Uso de la nube
-
Uso de dispositivos locales
Vamos a repasarlos uno por uno.
Cómo utilizar Stable Diffusion Online
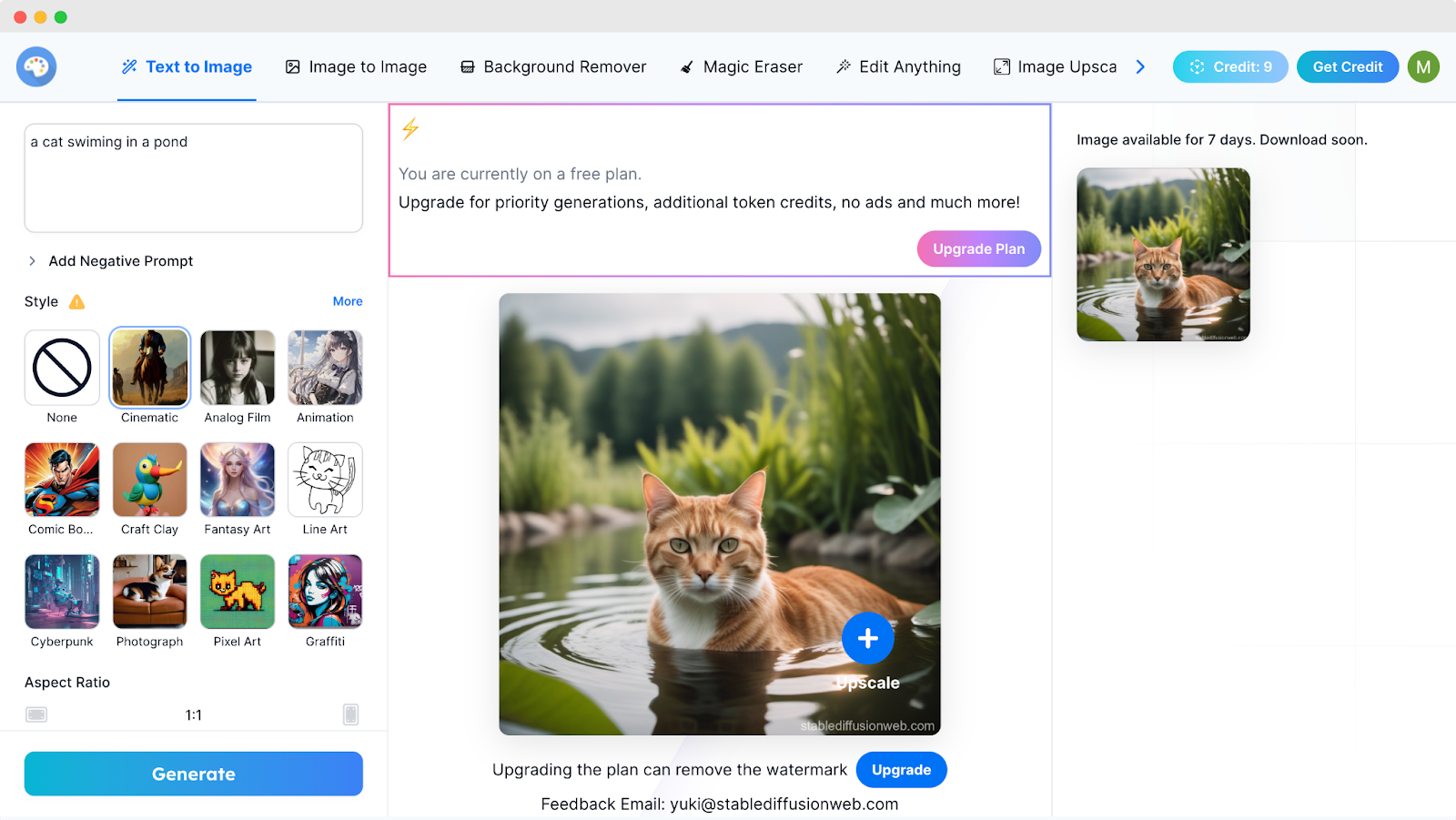
Es la forma más fácil de utilizar Stable Diffusion. Sigue los pasos que se indican a continuación para utilizar la herramienta.
-
Visita stablediffusionweb.com y regístrate para obtener una cuenta gratuita.
-
Escribe tu tema.
-
Elige un estilo, como «Cinemático», «Animación», «Pixel Art», etc.
-
Define la relación de aspecto y el número de imágenes que deseas.
-
Pulsa el botón «Generar ».
La plataforma en línea te ofrecerá las siguientes funciones:
-
De imagen a imagen
-
Texto a imagen
-
Eliminador de fondo
-
Borrador mágico
-
Mejorador de calidad de imagen
-
Cambiador de ropa con IA
-
Creador de retratos con IA
-
De boceto a imagen
La versión gratuita te permitirá acceder a las funciones básicas. Funciona con un sistema de créditos que se puede ampliar mediante la compra de sus planes mensuales o anuales. ¡Además, tendrás acceso a todas las funciones premium!
¡Hasta ahora, los planes más económicos cuestan a partir de 7 dólares al mes y dan acceso a casi todas las funciones!
Uso de Stable Diffusion en la nube
Esta es la mejor forma y la más eficaz de acceder a Stable Diffusion. Puedes acceder a Stable Diffusion a través de los servicios en la nube que ofrecen diferentes empresas.
Además, optimizan las funciones de personalización y de sugerencias de texto para ofrecerte una mejor experiencia de usuario. A continuación, la plataforma recurre al modelo Stable Diffusion para generar el arte generado por IA que prefieras.
Uso de Stable Diffusion en un dispositivo local
A diferencia de los modelos tradicionales de IA generativa, Stable Diffusion permite al usuario instalarlo en su dispositivo local. Gracias a su procesamiento eficiente, supera las limitaciones de la mayoría de los modelos de IA.
Muchos usuarios prefieren que sus datos sean privados y desean ejecutar Stable Diffusion en sus dispositivos. Existen programas que facilitan la configuración de Stable Diffusion en el dispositivo.
Al ser de código abierto, Stable Diffusion se puede utilizar de forma gratuita tanto en Mac como en PC.
Para ejecutar Stable Diffusion en tu ordenador, tu dispositivo debe cumplir los requisitos mínimos de hardware:
-
Un sistema operativo de 64 bits
-
Al menos 8 GB de RAM
-
Tarjeta gráfica con un mínimo de 6 GB de memoria de vídeo
-
Aproximadamente 10 GB de capacidad de almacenamiento
-
El instalador de Miniconda3
-
Archivos de GitHub para Stable Diffusion
Instalación local frente a instalación en la nube de Stable Diffusion
El uso de Stable Diffusion en dispositivos locales y en servicios en la nube tiene sus propias ventajas.
Estas son las principales diferencias entre utilizar Stable Diffusion en un dispositivo local y en servicios en la nube:
| Característica | Local | Nube |
| Coste | Requiere una inversión en hardware compatible | Pago por uso para recursos en la nube. |
| Requisitos de hardware | Se requiere una GPU con un mínimo de 6 GB de VRAM | No se necesita una tarjeta gráfica dedicada |
| Configuración | Requiere una instalación y configuración manuales | No es necesario realizar ninguna configuración ni instalación. |
| Control | Control total sobre el proceso y los datos. | El control depende de los límites del proveedor de servicios en la nube |
| Rendimiento | Depende del hardware local | Procesamiento más rápido en función de los distintos paquetes |
| Escalabilidad | Limitado a los recursos del equipo local | Es muy escalable y se puede ampliar para acceder a recursos más potentes. |
| Privacidad | Los datos son privados y están protegidos en los dispositivos locales. | Los datos se almacenan en los servidores del proveedor de servicios en la nube, que pueden ser utilizados por dicho proveedor. |
Preguntas frecuentes sobre «¿Qué es Stable Diffusion?», respondidas
¿Cuáles son algunas alternativas a Stable Diffusion?
RunDiffusion, Midjourney, Dall-E y Craiyon son algunas alternativas potentes a Stable Diffusion.
¿Se puede ejecutar Stable Diffusion en una CPU?
Sí, Stable Diffusion puede ejecutarse en una CPU. Sin embargo, no será tan rápido como un resultado procesado con una GPU. Dependiendo de la velocidad de procesamiento de la CPU y del tamaño de la imagen, generar un resultado con Stable Diffusion puede llevar varios minutos.
¿Se puede instalar Stable Diffusion en el móvil?
No es posible instalar ni ejecutar Stable Diffusion en un dispositivo móvil. Stable Diffusion requiere una GPU con un mínimo de 6 gigabytes de VRAM, algo imposible de conseguir en los móviles.
Palabras finales
Entonces, ¿por qué deberías usar Stable Diffusion?
El modelo Stable Diffusion está disponible de forma gratuita gracias a varias interfaces de terceros. Además, permite ejecutar el modelo en tu propio ordenador.
Cuenta con una comunidad cada vez más numerosa dedicada a la experimentación y el desarrollo del modelo. El carácter de código abierto del modelo permite una mayor libertad y participación por parte de los usuarios.
Stable Diffusion se encuentra todavía en una fase inicial y va evolucionando poco a poco. Solo podemos esperar grandes cosas de este modelo en los próximos días.
